
牛津、英伟达等提出记忆压缩新范式:训练时让模型学会断舍离
牛津、英伟达等提出记忆压缩新范式:训练时让模型学会断舍离2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。
来自主题: AI技术研报
10483 点击 2026-06-02 11:23
 搜索
搜索
2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。

今天在各大信息渠道看到 Llama4 发布的消息,一上来就放出三个模型,具体能力这里就不在赘述,相信大家已经多少看到不少介绍了。
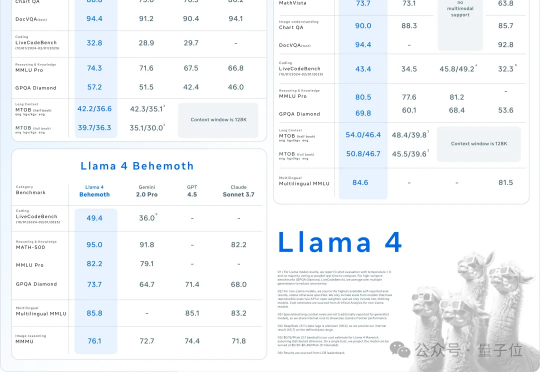
AI不过周末,硅谷也是如此。大周日的,Llama家族上新,一群LIama 4就这么突然发布了。这是Meta首个基于MoE架构模型系列,目前共有三个款:Llama 4 Scout、Llama 4 Maverick、Llama 4 Behemoth。